اسویام رتبهبندی
در یادگیری ماشین، یک SVM رتبهبندی گونهای از الگوریتم ماشین بردار پشتیبانی است که برای حل مسائل رتبهبندی خاص (از طریق یادگیری رتبهبندی) استفاده میشود. الگوریتم SVM رتبهبندی توسط Thorsten Joachims در سال ۲۰۰۲ منتشر شد.[۱] هدف اصلی این الگوریتم بهبود عملکرد یک موتور جستجوی اینترنتی بود. با این حال، مشخص شد که رتبهبندی SVM همچنین میتواند برای حل مسائل دیگری مانند Rank SIFT استفاده شود.[۲]
توصیف
الگوریتم رتبهبندی SVM یک تابع بازیابی یادگیری است که از روشهای رتبهبندی زوجی برای مرتبسازی تطبیقی نتایج بر اساس «مرتبط بودن» آنها برای یک پرسوجو خاص استفاده میکند. تابع رتبهبندی SVM از یک تابع نگاشت برای توصیف تطابق بین یک عبارت جستجو و ویژگیهای هر یک از نتایج ممکن استفاده میکند. این تابع نگاشت هر جفت داده (مثلاً یک پرس و جوی جستجو و صفحه وب کلیک شده) را به یک فضای ویژگی تصویر میکند. این ویژگیها با دادههای کلیکی مربوطه ترکیب میشوند (که میتواند به عنوان یک واسط برای ارتباط یک صفحه برای یک جستجوی خاص عمل کند) و سپس میتواند به عنوان دادههای آموزشی برای الگوریتم رتبهبندی SVM استفاده شود.
بهطور کلی، رتبهبندی SVM شامل سه مرحله در دوره آموزش است:
- یک نگاشت از شباهتهای بین پرسوجوها و صفحات کلیکشده به در یک فضای ویژگی خاص تعریف میکند.
- فاصله بین هر دو بردار به دست آمده در مرحله ۱ را محاسبه میکند.
- این یک مسئله بهینهسازی را تشکیل میدهد که شبیه به یک طبقهبندی استاندارد SVM است و این مشکل را با حل کننده SVM معمولی حل میکند.
زمینه
روش رتبهبندی
فرض کنید مجموعه دادهای است که شامل عنصر است. یک روش رتبهبندی است که به اعمال میشود. سپس در را میتوان به صورت یک ماتریس دودویی نشان داد. اگر رتبه از رتبه بالاتر باشد، یعنی:







آنگاه درایه متناظر با آن را در ماتریس مقدار ۱ و در غیر این صورت مقدار ۰ قرار میدهیم.
تای کندال همچنین به ضریب همبستگی رتبه تای کندال اشاره دارد، که معمولاً برای مقایسه دو روش رتبهبندی برای یک مجموعه داده استفاده میشود.
فرض کنید و دو روش رتبهبندی باشد که برای مجموعه دادههای اعمال میشود، تای کندال بین و را میتوان به صورت زیر نشان داد:



که در آن تعداد جفتهای همخوان است و تعداد جفتهای ناسازگار (وارونگی) است. یک جفت و همخوان است اگر در هر دو روش و رتبهبندی و یکسان باشد. در غیر این صورت ناسازگار خواهند بود.






کیفیت بازیابی اطلاعات معمولاً با سه معیار زیر ارزیابی میشود:
- صحت، درستی (Precision)
- فراخوانی، حساسیت (Recall)
- دقت متوسط (Average Precision)
برای یک پرس و جو خاص به یک پایگاه داده، فرض کنید مجموعه ای از عناصر اطلاعاتی مرتبط در پایگاه داده و مجموعه ای از عناصر اطلاعاتی بازیابی شده باشد. سپس سه اندازهگیری فوق را میتوان به صورت زیر نشان داد:



که در آن دقت فراخوانی است.

فرض کنید و به ترتیب روشهای رتبهبندی مورد انتظار و پیشنهادی یک پایگاه داده باشند، کران پایین میانگین دقت روش را میتوان به صورت زیر نشان داد.


![{\displaystyle AvgPrec(r_{f(q)})\geqq {1 \over R}\left[Q+{\binom {R+1}{2}}\right]^{-1}(\sum _{i=1}^{R}{\sqrt {i}})^{2}}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/f96dcfba5cc4265e4d0dc87b272c6f47bfc90a29.svg)
که در آن تعداد درایههای متفاوت در قسمت بالای قطر اصلی ماتریس های و و تعداد عناصر مرتبط در مجموعه داده است.

طبقهبندی SVM[۸]
فرض کنید عنصر یک مجموعه داده آموزشی که در آن بردار ویژگی و برچسب (که دسته را مشخص میکند) است. یک طبقهبندی کننده SVM معمولی برای چنین مجموعه دادهای میتواند به عنوان راه حل مسئله بهینهسازی زیر تعریف شود.




حل مسئله بهینهسازی فوق را میتوان به صورت ترکیبی خطی از بردارهای ویژگی نشان داد.


که در آن ضرایبی هستند که باید تعیین شوند.

الگوریتم رتبهبندی SVM
تابع زیان
فرض کنید تای کندال بین روش رتبهبندی مورد انتظار و روش پیشنهادی باشد، میتوان ثابت کرد که به ماکسیمم کردن به مینیمم کردن کران پایینِ میانگینِ دقت کمک میکند.

- تابع زیان مورد انتظار[۹]
منفی را میتوان به عنوان تابع زیان برای به حداقل رساندن کران پایین میانگین دقت انتخاب کرد.

که در آن توزیع آماری به پرس و جو خاص است.


- تابع زیان تجربی
از آنجایی که تابع زیان مورد انتظار قابل پیادهسازی نیست، تابع زیان تجربی زیر در عمل برای دادههای آموزشی انتخاب میشود.

جمعآوری دادههای آموزشی
پرس و حوی iid روی یک پایگاه داده اعمال میشوند و هر پرس و جو با یک روش رتبهبندی مطابقت دارد. مجموعه دادههای آموزشی عنصر دارد. هر عنصر حاوی یک پرس و جو و روش رتبهبندی مربوطه است.

فضای ویژگی

یک نگاشت [۱۰][۱۱] مورد نیاز است که هر پرس و جو و عنصر پایگاه داده را به فضای ویژگی مورد نیاز متناظر کند. سپس هر نقطه در فضای ویژگی با روش رتبهبندی با رتبه خاصی برچسب گذاری میشود.

مسئله بهینهسازی
نقاط تولید شده توسط دادههای آموزشی در فضای ویژگی قرار دارند که حاوی اطلاعات رتبه (برچسبها) نیز میباشد. از این نقاط برچسب زده شده میتوان برای یافتن مرز (طبقهبندی) که ترتیب آنها را مشخص میکند استفاده کرد. در حالت خطی، چنین مرزی (طبقهبندی کننده) یک بردار است.
فرض کنید و دو عنصر در پایگاه داده هستند و مینویسیم اگر رتبه از بالاتر از در روش رتبهبندی معین باشد. فرض کنید بردار کاندیدای طبقهبندی کننده خطی در فضای ویژگی باشد. آنگاه مسئله رتبهبندی را میتوان به مسئله طبقهبندی SVM زیر ترجمه کرد. توجه داشته باشید که یک روش رتبهبندی با یک پرس و جو مطابقت دارد.



مسئله بهینهسازی فوق با مسئله طبقهبندی SVM کلاسیک یکسان است، به همین دلیل است که این الگوریتم Ranking-SVM نامیده میشود.
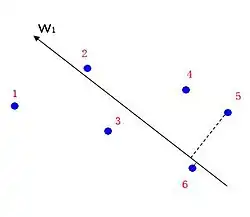
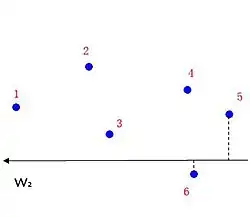
تابع بازیابی
بردار بهینه که توسط نمونه آموزشی به دست آمده است، چنین است:


بنابراین تابع بازیابی را میتوان بر اساس چنین طبقهبندی بهینه ای تشکیل داد.
برای پرس و جوی جدید ، تابع بازیابی ابتدا تمام عناصر پایگاه داده را به فضای ویژگی تصویر میکند. سپس این نقاط ویژگی را بر اساس مقادیر ضرب داخلی آنها با بردار بهینه مرتب میکند. و رتبه هر نقطه ویژگی، رتبه عنصر مربوطه پایگاه داده برای پرس و جوی است.
کاربرد رتبهبندی SVM
رتبهبندی SVM میتواند برای رتبهبندی صفحات بر اساس پرس و جو اعمال شود. الگوریتم را میتوان با استفاده از دادههای کلیکی آموزش داد که از سه بخش زیر تشکیل شده است:
- پرس و جو.
- رتبهبندی فعلی نتایج جستجو
- نتایج جستجو توسط کاربر کلیک شده است
ترکیب ۲ و ۳ نمیتواند ترتیب دادههای آموزشی کاملی را که برای اعمال الگوریتم کامل SVM لازم است را ارائه دهد. در عوض، بخشی از اطلاعات رتبهبندی دادههای آموزشی را ارائه میدهد؛ بنابراین الگوریتم را میتوان به صورت زیر کمی اصلاح کرد.

روش اطلاعات رتبهبندی کل مجموعه داده را ارائه نمیدهد، بلکه زیر مجموعه ای از روش رتبهبندی کامل است؛ بنابراین شرط مسئله بهینهسازی در مقایسه با Ranking-SVM اصلی راحت تر میشود.

منابع
- ↑ Joachims, T. (2002), "Optimizing Search Engines using Clickthrough Data", Proceedings of the ACM Conference on Knowledge Discovery and Data Mining
- ↑ Bing Li; Rong Xiao; Zhiwei Li; Rui Cai; Bao-Liang Lu; Lei Zhang; "Rank-SIFT: Learning to rank repeatable local interest points",Computer Vision and Pattern Recognition (CVPR), 2011
- ↑ M.Kemeny. Rank Correlation Methods, Hafner, 1955
- ↑ A.Mood, F. Graybill, and D. Boes. Introduction to the Theory of Statistics. McGraw-Hill, 3rd edition, 1974
- ↑ J. Kemeny and L. Snell. Mathematical Models in THE Social Sciences. Ginn & Co. 1962
- ↑ Y. Yao. Measuring retrieval effectiveness based on user preference of documents. Journal of the American Society for Information Science, 46(2): 133-145, 1995.
- ↑ R.Baeza- Yates and B. Ribeiro-Neto. Modern Information Retrieval. Addison- Wesley-Longman, Harlow, UK, May 1999
- ↑ C. Cortes and V.N Vapnik. Support-vector networks. Machine Learning Journal, 20: 273-297,1995
- ↑ V.Vapnik. Statistical Learning Theory. WILEY, Chichester,GB,1998
- ↑ N.Fuhr. Optimum polynomial retrieval functions based on the probability ranking principle. ACM TRANSACTIONS on Information Systems, 7(3): 183-204
- ↑ N.Fuhr, S. Hartmann, G. Lustig, M. Schwantner, K. Tzeras,and G. Knorz. Air/x - a rule-based multistage indexing system for large subject fields. In RIAO,1991