تحلیل پوششی دادهها
تحلیل پوششی دادهها (Data Envelopment Analysis - DEA) یک روش ناپارامتریک مبتنی بر برنامهریزی ریاضی است که برای ارزیابی و مقایسه کارایی نسبی مجموعهای از واحدهای همگن، که به آنها واحدهای تصمیمگیرنده (Decision Making Units - DMUs) گفته میشود، بهکار میرود. این روش با استفاده از دادههای ورودی و خروجی واقعی، بدون نیاز به فرض شکل تابع تولید، مرز کارایی را بر اساس عملکرد بهترین واحدها ترسیم میکند و سایر واحدها را نسبت به این مرز میسنجد. DEA امکان شناسایی واحدهای کارا، اندازهگیری میزان ناکارایی و ارائه اهداف و الگوهای قابل دستیابی برای واحدهای ناکارا را فراهم میسازد. انعطافپذیری این روش در برخورد با چندین ورودی و خروجی بهطور همزمان و عدم وابستگی آن به فرضیات آماری، باعث شده است که در حوزههای مختلفی همچون بانکداری، آموزش، بهداشت، حملونقل و صنایع تولیدی بهطور گسترده مورد استفاده قرار گیرد.[۱]

در واقع تحلیل پوششی دادهها روشی مبتنی بر برنامهریزی خطی میباشد که به کمک آن ارزیابی عملکرد برای سیستم های با ورودی ها و خروجی های چندگانه انجام می شود. با توجه به اینکه روش های قدیمی تر مرسوم بود از یک تابع از پیش تعیین شده برای این کار استفاده کنند(تابع تولید ) و در تحلیل پوششی داده ها چنین نیست، به آن ناپارمتریک گفته می شود. در این روش منحنی مرزی کارا از یک سری نقاط که به آن ها DMU های کارا گفته می شود، ایجاد میگردد. [۲] یکی از تمایزهای اساسی تحلیل پوششی دادهها (DEA) نسبت به بسیاری از روشهای دیگر ارزیابی عملکرد، قابلیت الگویابی آن است. در DEA، الگو یا مرجع برای هر واحد تصمیمگیرنده (DMU) بهطور مستقیم از میان واحدهای واقعی و موجود در جامعه مورد مطالعه استخراج میشود. این امر باعث میشود که الگو نهتنها قابل حصول و دسترسی باشد، بلکه بهطور عملی نیز بتوان به آن دست یافت، زیرا حاصل ترکیب یا تقلید از عملکرد واقعی واحدهای کارآمد موجود است. [۳]
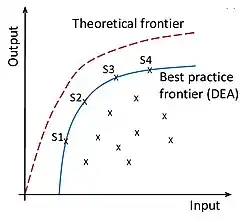
پایه و اساس این ویژگی، مجموعه امکان تولید (Production Possibility Set) در تحلیل پوششی داده هااست. این مجموعه با توجه به ویژگیهای واقعی جامعه تحت ارزیابی و بر اساس اصول و فروض حاکم بر آن (مانند بازده به مقیاس ثابت یا متغیر، قابلیت تقسیمپذیری و عدم تولید منفی) ساخته میشود. بنابراین، هر الگویی که در چارچوب این مجموعه تعیین میشود، الزاماً با شرایط واقعی و محدودیتهای حاکم بر جامعه سازگار است. [۴]
این مزیت در بسیاری از روشهای دیگر ارزیابی عملکرد وجود ندارد؛ در روشهای غیر-DEA، الگو یا نقطه مرجع ممکن است حاصل مدلهای تئوریک، میانگینهای آماری یا مقادیر ایدهآل و غیرقابل حصول باشد که لزوماً با ویژگیها و محدودیتهای واقعی جامعه تحت بررسی همخوانی ندارند. از اینرو، DEA نهتنها در شناسایی الگو، بلکه در ارائه مسیر عملی برای دستیابی به آن، رویکردی متمایز و واقعبینانه دارد. [۵]
فرمولبندی ریاضی مدل CCR
در حالتی که تنها یک ورودی و یک خروجی وجود دارد، کارایی صرفاً نسبت خروجی به ورودی تولیدشده است، و مقایسهٔ چند واحد تصمیمگیرنده (DMU) بر اساس آن ساده میباشد. اما با افزودن ورودیها یا خروجیهای بیشتر، محاسبهٔ کارایی پیچیدهتر میشود. فرض کنید واحد تصمیمگیرنده (DMU) وجود دارد که هر کدام با مصرف ورودی، خروجی تولید میکنند. ورودیها و خروجیهای واحد تصمیمگیرندهٔ ام بهصورت زیر نمایش داده میشوند:





که در آن:
نشاندهندهٔ مقدار ورودی ام برای واحد ام است.


نشاندهندهٔ مقدار خروجی ام برای همان واحد است.


چارنز، کوپر و رودز (۱۹۷۸)[۶] در مدل پایهٔ DEA خود (مدل CCR) تابع هدف را برای یافتن کارایی به صورت چنین تعریف کردند:



رابطهٔ بالا در حقیقت نسبت مجموع وزندار خروجیها به مجموع وزندار ورودیها است. وزنهای مربوط به خروجیها و وزنهای مربوط به ورودیها هستند که به مدل اجازه میدهند اهمیت نسبی هر ورودی و خروجی در محاسبهٔ کارایی در نظر گرفته شود. امتیاز کارایی یا همان نمرهٔ کارایی بهدنبال بیشینهسازی است، با این قید که استفاده از همان وزنها برای هر موجب نشود که هیچ امتیاز کاراییای از یک بیشتر شود:




و همه ورودیها، خروجیها و وزنها باید غیرمنفی باشند. برای امکانپذیر شدن بهینهسازی خطی، معمولاً یا مجموع خروجیها یا مجموع ورودیها را به یک مقدار ثابت (معمولاً ۱) مقید میکنند. فرم خطی شده مدل CCR در ماهیت ورودی به صورت زیر است:

مساله بالا برای هر DMU باید به طور جداگانه حل شود و مقدار تابع هدف آن بعنوان کارایی برای آن ها در نظر گرفته می شود. این مقدار همواره بین صفر و یک است.
از آنجا که تعداد پارامترهای مسألهٔ بهینهسازی در مدلهای DEA برابر با مجموع تعداد ورودیها و خروجیها است ()، گزینشِ مجموعه ورودیها/خروجیها که فرآیند مورد مطالعه را بهدرستی توصیف کند اهمیت اساسی دارد. بهعلاوه، به طور تجربی نتایج نشان داده شده است در شرایطی که محدودیت های وزنی وجود ندارد بهتر است برای قابل تحلیل بودن نتایج شرایط زیر روی تعداد DMUها برقرار باشد.


مثال
فرض کنید دادههای زیر در دسترس باشند:
واحد ۱ در روز ۱۰۰ کالا تولید میکند و ورودیهای مورد نیاز برای هر کالا شامل ۱۰ دلار مواد اولیه و ۲ ساعتکار است.
واحد ۲ در روز ۸۰ کالا تولید میکند و ورودیها شامل ۸ دلار مواد اولیه و ۴ ساعتکار هستند.
واحد ۳ در روز ۱۲۰ کالا تولید میکند و ورودیها شامل ۱۲ دلار مواد اولیه و ۱٫۵ ساعتکار هستند.
برای محاسبهٔ کارایی واحد ۱، تابع هدف بهصورت زیر تعریف میشود:

که تحت قیود زیر قرار دارد (کارایی سایر واحدها نباید از ۱ بیشتر شود):
کارایی واحد ۱:

کارایی واحد ۲:

کارایی واحد ۳:

و همچنین شرط عدم منفی بودن:

از آنجا که یک کسر با متغیرهای تصمیم در صورت و مخرج، غیرخطی است و ما از تکنیک برنامهریزی خطی استفاده میکنیم، باید مدل را خطیسازی کنیم. در این حالت، مخرج تابع هدف ثابت (اینجا برابر ۱) در نظر گرفته میشود و صورت بیشینه میگردد.
فرمولبندی جدید به شکل زیر خواهد بود:

تاریخچه
تحلیل پوششی دادهها (DEA) اولینبار در سال ۱۹۷۸ توسط چارنِز، کوپر و رودز در مقالهای با عنوان Measuring the Efficiency of Decision Making Units [۷] معرفی شد، این مقاله در پایگاه استنادی اسکوپوس [۸] تا اواسط سال 2025 دارای بیش از 22 هزار ارجاع است؛ آنها برای نخستین بار مرز کارایی تولید را بهصورت تجربی با استفاده از برنامهریزی خطی تعیین کردند. ریشههای نظری این روش به کار مایکل جی. فارل (۱۹۵۷) بازمیگردد، که مفاهیم اولیه بهرهوری را مطرح کرد و بعدها توسط چارنِز و همکاران بازشناسی شد. از زمان ارائه، مدلهای گوناگون مانند BCC، مدلهای شبکهای، DEA فازی و شاخص مالموئیست گسترش یافتهاند تا توان عملیاتی و تحلیلی این روش را افزایش دهند. [۹]

در ایران اما این تکنیک اولین بار در رساله دکتری، دکتر محمد رضا علیرضایی در دانشگاه خوارزمی (تربیت معلم سابق) به راهنمایی دکتر غلامرضا جهانشاهلو مورد بررسی قرار گرفت. دکتر غلامرضا جهانشاهلو که از ایشان بعنوان پدر علم تحلیل پوششی داده ها در ایران یاد می شود، به تربیت شاگردان زیادی پرداخت که از جمله شاخص ترین آن ها می توان به به دکتر فرهاد حسین زاده لطفی، دکتر علیرضا امیر تیموری، دکتر مجید سلیمانی دامنه و دکتر محمد خدابخشی اشاره کرد[۱۰]. این موضوع در دهه هفتاد شمسی در ایران آغاز شد. که منجر به چاپ اولین مقاله های علمی در این سال ها گردید. مدل MAJ [۱۱] که برگفته از حروف ابتدایی نام نویسندگان آن (Mehrabian-Alirezaei-Jahanshahloo) مقاله می باشد، یکی از همین اولین مقالات علمی ایران در حوزه تحلیل پوششی داده ها است. از حروف ابتدایی نام نویسندگان آن (Mehrabian-Alirezaei-Jahanshahloo) مقاله می باشد.


در اواسط دهه هفتاد شمسی، با تأسیس دورههای تحصیلات تکمیلی در دانشگاههای معتبر کشور و دوراندیشی دکتر غلامرضا جهانشاهلو، موضوع DEA بهصورت گسترده در پایاننامهها و رسالههای دکتری مورد استفاده قرار گرفت. همزمان با این روند، نخستین همایشها و کارگاههای تخصصی تحلیل پوششی دادهها در ایران برگزار شد و به تدریج منجر به شکلگیری انجمن ایرانی تحلیل پوششی دادهها گردید. این انجمن از اوایل دهه نود شمسی نقش مهمی در سازماندهی جامعه پژوهشی DEA ایفا کرد و بستری فراهم آورد که ایران به یکی از قطبهای علمی این حوزه در جهان بدل شود. این تولید دانش و کار گروهی شاگردان دکتر جهانشاهلو در دهه های بعد چنان رشد شگفت انگیزی داشت که کشور ایران در جستجو با کلید واژه(data envelopment analysis) با 5780 سند علمی (مقاله، کتاب و ...) در پایگاه اسکوپوس (Scopus) [۱۲] رتبه سوم بعد از کشور های چین و آمریکا را داراست (تاریخ جستجو 2025/08)، که افتخار ارزشمندی برای جامعه علمی ایران است. شاید بررسی شرایط تولید علم در ایران ارزش این موضوع را دوچندان کند.
انجمن ایرانی تحلیل پوششی دادهها به منظور گسترش و پیشبرد و ارتقای علمی و تصمیم گیری و توسعه کیفی نیروهای متخصص و بهبود بخشیدن به امور آموزشی و پژوهشی در زمینه تحلیل پوششی داده ها تشکیل گردید.
وظایف و اهداف انجمن عبارتند از: 1-انجام تحقیقات علمی و فرهنگی در سطح ملی و بینالمللی با محققان و متخصصانی که به گونهای با علوم ریاضی، صنایع و مدیریت سر و کار دارند. 2-همکاری با نهادهای اجرایی، علمی و پژوهشی در زمینه ارزیابی و بازنگری و اجرای طرحها و برنامههای مربوط به امور آموزش و پژوهش در زمینه علمی موضوع فعالیت انجمن. 3-ترغیب و تشویق پژوهشگران و تجلیل از محققان و استادان ممتاز. 4- ارائه خدمات آموزشی و پژوهشی و فنی 5- برگزاری گردهماییهای علمی در سطح ملی، منطقهای و بینالمللی 6- انتشار کتب و نشریات علمی.

کاربرد
تحلیل پوششی دادهها (DEA) بهعنوان یک ابزار ناپارامتری قدرتمند، در زمینههای گوناگونی بهکار گرفته میشود؛ از بانکداری و آموزش تا حوزههای پیشرفتهای همچون مدیریت منابع سلامتی و تصمیمگیری چندمعیاره. در حوزه عمومیتر، DEA برای مقایسه کارایی شعب بانکها[۱۳] ، مدارس[۱۴]، بیمارستانها[۱۵]، ادارات پست[۱۶] و بخشهای صنعتی مورد استفاده قرار میگیرد. این کاربردها بیشتر مبتنی بر تعیین واحدهای کارا و ناکارا و ارائه راهبردهایی برای بهبود عملکرد هستند. در حوزه سلامت, DEA برای تحلیل عملکرد بخشهای اورژانس بیمارستانی[۱۷] بسیار کاربردی است. پژوهشها نشان میدهند DEA در بررسی عملکرد در زمانهای بحرانی مانند سکته مغزی حاد یا انفارکتوس میوکارد موثر است و قابلیت ادغام با روشهایی مانند تحلیل چندمعیاره (MCDM)[۱۸] و یادگیری ماشین را دارد. در سطح اقتصاد، تامینکننده پایدار و علوم مدیریت, این روش برای ارزیابی کارایی انتخاب تامینکنندگان پایدار در زنجیره تأمین[۱۹] بهکار رفته است. همچنین در کاربردهای بینالمللی، DEA در انتخاب بازارهای هدف برای صادرات محصولات (مثل از اسپانیا) استفاده میشود؛ بهویژه در مدل ها با ماهیت ترکیبی که بهرهوری و هزینه را بهصورت همزمان تحلیل میکند. در زمینه آموزش و پژوهش, DEA برای ارزیابی کارایی تحقیقات دانشگاهها، فعالیتهای پژوهشی و عملکرد پژوهشگران نیز کاربرد دارد. بهعنوان مثال، در مطالعهای برای سیستم دانشگاههای ایتالیا، DEA برای تعیین کارایی فنی و هزینهای فعالیتهای پژوهشی استفاده شده بود.همچنین در ایران، DEA در یک مطالعه موردی برای ارزیابی عملکرد پژوهشگران سازمانهای تحقیقاتی مورد استفاده قرار گرفته است . جالب است بدانید در حوزههای خاص و نوظهور، DEA وارد عرصههایی مانند برنامههای تبادل کلیه (kidney exchange programs) نیز شده است. در این زمینه، این روش برای ارزیابی عدالت در تخصیص منابع (نظیر دسترسی، اولویت و نتایج) بهکار رفته و ناهماهنگیهای گروهی میان اقوام مختلف را مورد بررسی قرار داده است.
نرمافزارها
در تحلیل پوششی دادهها (DEA)، انتخاب نرمافزار مناسب بستگی به نیازهای خاص پروژه، حجم دادهها، پیچیدگی مدلها و سطح تجربه کاربر دارد. در این راستا، زبانهای برنامهنویسی مختلفی مانند R و Python، و همچنین نرمافزارهای تخصصی مانند GAMS و MATLAB برای پیادهسازی مدلهای DEA مورد استفاده قرار میگیرند.
زبان R با داشتن کتابخانههای متعددی مانند deaR و Benchmarking، ابزارهای قدرتمندی برای انجام تحلیل پوششی دادهها ارائه میدهد. این کتابخانهها امکان پیادهسازی مدلهای مختلف DEA، از جمله مدلهای کلاسیک و فازی، را فراهم میکنند و برای تحلیل دادههای آماری و گرافیکی مناسب هستند.
در Python، کتابخانههایی مانند PyDEA و dealib برای تحلیل پوششی دادهها توسعه یافتهاند. این کتابخانهها ابزارهای ساده و کاربرپسندی برای پیادهسازی مدلهای DEA ارائه میدهند و بهویژه برای تحلیل دادههای بزرگ و پیچیده مناسب هستند.
MATLAB با داشتن ابزارهایی مانند DEA Toolbox و Data Envelopment Analysis، محیطی مناسب برای پیادهسازی مدلهای DEA فراهم میکند. این ابزارها امکان انجام محاسبات پیچیده و تحلیلهای آماری را با استفاده از زبان برنامهنویسی MATLAB فراهم میآورند.
GAMS (General Algebraic Modeling System) یک زبان مدلسازی ریاضی است که برای حل مسائل بهینهسازی پیچیده طراحی شده است. در تحلیل پوششی دادهها، GAMS با استفاده از زبان مدلسازی ریاضی خود، امکان پیادهسازی مدلهای DEA را فراهم میکند. این نرمافزار بهویژه برای مدلهای با تعداد متغیر و محدودیتهای زیاد مناسب است.
به طور کلی می توان گفت انتخاب نرمافزار مناسب برای تحلیل پوششی دادهها بستگی به نیازهای خاص پروژه و سطح تجربه کاربر دارد. برای پروژههای آماری و گرافیکی، R گزینه مناسبی است. برای تحلیل دادههای بزرگ و پیچیده، Python مناسبتر است. برای انجام محاسبات پیچیده، MATLAB و GAMS ابزارهای قدرتمندی ارائه میدهند. در نهایت، انتخاب نرمافزار باید با توجه به ویژگیهای خاص پروژه و نیازهای تحلیل انجام شود.
R
یکی از نرمافزارهای کاربردی و پرطرفدار در حوزه تحلیل پوششی دادهها، نرمافزار R است که بهدلیل قابلیتهای قدرتمند در برنامهنویسی و حل مسائل بهینهسازی، توجه ویژهای به آن شده است. کتابی که توسط دکتر فرهاد حسین زاده لطفی و همکارانش [۲۰] تهیه شده است، بهصورت جامع و کاربردی، استفاده از کدهای پایه R را برای حل مسائل بهینهسازی در زمینه DEA معرفی میکند.
این کتاب با ارائه مباحث مقدماتی در زمینه تحلیل پوششی دادهها و مجموعههای فازی، ابتدا تعاریف و مفاهیم لازم را شرح میدهد. سپس به مدلهای DEA در محیطهای «ساده (Crisp)» و «فازی (Fuzzy)» پرداخته و مدلهای ریاضی مرتبط را با مثالهای متعدد تشریح میکند.

ساختار کتاب شامل بخشهایی از جمله:
معرفی تحلیل پوششی دادهها و مجموعههای فازی (صفحات ۱ تا ۱۷)
معرفی و آموزش مقدماتی نرمافزار R (صفحات ۱۹ تا ۵۲)
مدلهای پایه DEA همراه با کدهای R (صفحات ۵۳ تا ۹۸)
مدلهای پیشرفته DEA با کدهای R (صفحات ۹۹ تا ۱۶۲)
مدلهای DEA فازی همراه با کدهای R (صفحات ۱۶۳ تا ۲۳۶)
در این کتاب، کدهای برنامهنویسی R بر اساس دادههای واقعی نوشته شده و به کاربران امکان میدهد که خودشان مدلهای DEA و DEA فازی را پیادهسازی و تحلیل کنند. به این ترتیب، علاوه بر یادگیری تئوری، مهارت کاربردی و توانایی حل مسائل پیچیده با کمک نرمافزار R نیز فراهم میشود.
Python
در سالهای اخیر، زبان برنامهنویسی پایتون بهعنوان ابزاری قدرتمند در تحلیل پوششی دادهها (DEA) شناخته شده است. کتابخانههای متعددی در این زمینه توسعه یافتهاند که هرکدام ویژگیها و قابلیتهای خاص خود را دارند. در ادامه به معرفی برخی از این کتابخانهها میپردازیم:
1. pyDEA [۲۱] کتابخانه pyDEA یک ابزار جامع برای انجام تحلیل پوششی دادهها در پایتون است. این کتابخانه از رابطهای مختلفی مانند رابط گرافیکی (GUI)، رابط خط فرمان (CLI) و همچنین امکان استفاده مستقیم در اسکریپتهای پایتون پشتیبانی میکند. کاربران میتوانند دادههای ورودی را بارگذاری کرده، مدلهای DEA را اجرا کرده و نتایج را ذخیره کنند. pyDEA از مدلهای مختلفی مانند مدلهای بازده به مقیاس متغیر (VRS) و ثابت (CRS) پشتیبانی میکند و برای نصب آن میتوان از دستور زیر استفاده کرد:
pip install pyDEA
برای اطلاعات بیشتر و مستندات، میتوانید به صفحه رسمی pyDEA مراجعه کنید.
2. dealib [۲۲] کتابخانه dealib یک ابزار سبک و کاربرپسند برای انجام تحلیل پوششی دادهها است. این کتابخانه از مدلهای مختلفی مانند مدلهای انحرافی (Slack)، ضربی (Multiplier)، جمعی (Additive) و مدلهای فوقکارایی (Super-efficiency) پشتیبانی میکند. همچنین، امکان تعیین جهتگیری ورودی (Input) یا خروجی (Output) و بازده به مقیاس متغیر (VRS) یا ثابت (CRS) را فراهم میآورد. برای نصب این کتابخانه میتوان از دستور زیر استفاده کرد:
pip install dealib
مستندات کامل آن در صفحه رسمی dealib در دسترس است.
3. dea-tools [۲۳] کتابخانه dea-tools یک بسته نرمافزاری متنباز است که بهطور ویژه برای تحلیل دادههای زمیننگاری و سنجش از دور طراحی شده است. این کتابخانه شامل توابع و الگوریتمهایی برای بارگذاری، پردازش و تحلیل دادههای DEA است. برای نصب آن میتوان از دستور زیر استفاده کرد:
pip install dea-tools
برای اطلاعات بیشتر، میتوانید به صفحه رسمی dea-tools مراجعه کنید.
4. pyStoNED [۲۴] کتابخانه pyStoNED برای انجام تحلیل پوششی دادهها با استفاده از تابع فاصلهای جهتدار (Directional Distance Function) طراحی شده است. این کتابخانه امکان انجام مدلهای مختلف DEA را با توجه به ورودیها و خروجیهای مورد نظر فراهم میآورد. برای اطلاعات بیشتر، میتوانید به مستندات pyStoNED مراجعه کنید.
5. Pyomo [۲۵] کتابخانه Pyomo یک ابزار قدرتمند برای مدلسازی و حل مسائل بهینهسازی در پایتون است. اگرچه Pyomo بهطور خاص برای DEA طراحی نشده است، اما با استفاده از آن میتوان مدلهای DEA را بهصورت سفارشی پیادهسازی کرد. Pyomo از مدلسازی ریاضی با استفاده از زبان مدلسازی جبری (AML) پشتیبانی میکند و برای نصب آن میتوان از دستور زیر استفاده کرد:
pip install pyomo
برای اطلاعات بیشتر، میتوانید به صفحه رسمی Pyomo مراجعه کنید.
منابع
متن چپچینشده
- ↑ https://www.sciencedirect.com/science/article/pii/S0377221709003440?casa_token=mvVK1nDX4skAAAAA:-0WPBLnhiM5zsZnuGQLUs9tOFakqGjoSuqvtRB9ky-zeC9xcG6XteTv6fRfYE4-FtnR7MdPFC8I
- ↑ https://www.sciencedirect.com/science/article/pii/S0167637798000364?casa_token=So00MZJIUIQAAAAA:IU8T5Q6E7Bc18juan9IJ9yr6zbP1XLsZGVBbD1Vl8MbAVE2qPi8JYHnLXwCqZ-s5TaWwF83St0U
- ↑ https://books.google.com/books?hl=en&lr=&id=rBiGxrgFk-kC&oi=fnd&pg=PR3&dq=dea+benchmarking&ots=tRPcxuvUaq&sig=SlldmXiFr39QaKY1sHCGMygPpK8#v=onepage&q=dea%20benchmarking&f=false
- ↑ https://www.sciencedirect.com/science/article/pii/S0377221708001513?casa_token=ZuUh4yFd0WoAAAAA:26TSwuxTY9-DsNXqjO1Z0ZKPrDhe0jYwh9rO-WUUWP17_3ba4mv90My8s-fBXPahDeFEwRalJLI
- ↑ https://www.sciencedirect.com/science/article/pii/0305048389900297
- ↑ https://www.sciencedirect.com/science/article/pii/0377221778901388
- ↑ https://www.sciencedirect.com/science/article/pii/0377221778901388
- ↑ https://www.scopus.com/
- ↑ https://www.sciencedirect.com/science/article/pii/S0377221703004065?casa_token=XSI731kgzEAAAAAA:m32SCMS7tileHqda-CKuZ9KAp1UKFry7YiYyyW4HfVMhM5UNw9echqItNM0AHGPrm2_5CIV8AvE
- ↑ https://fa.ims.ir/wp-content/uploads/2019/06/%DB%8C%D8%A7%D8%AF%D9%86%D8%A7%D9%85%D9%87-%D8%B4%D8%A7%D8%AF%D8%B1%D9%88%D8%A7%D9%86-%D8%AF%DA%A9%D8%AA%D8%B1-%D8%BA%D9%84%D8%A7%D9%85%D8%B1%D8%B6%D8%A7-%D8%AC%D9%87%D8%A7%D9%86%D8%B4%D8%A7%D9%87%D9%84%D9%88-151-9.pdf
- ↑ https://link.springer.com/article/10.1023/a:1008703501682
- ↑ https://www.scopus.com/
- ↑ https://link.springer.com/article/10.1057/ces.2002.13
- ↑ https://www.sciencedirect.com/science/article/pii/S0272775797000484
- ↑ https://link.springer.com/article/10.1007/s10729-018-9436-8
- ↑ https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-8292.1995.tb00877.x
- ↑ https://www.sciencedirect.com/science/article/pii/S0038012122002282
- ↑ https://www.tandfonline.com/doi/abs/10.1057/palgrave.jors.2600800
- ↑ https://link.springer.com/article/10.1007/s10479-006-0026-7
- ↑ https://link.springer.com/book/10.1007/978-3-030-24277-0
- ↑ https://pypi.org/project/pyDEA
- ↑ https://pypi.org/project/dealib/
- ↑ https://pypi.org/project/dea-tools/
- ↑ https://pystoned.readthedocs.io/en/latest/
- ↑ https://www.pyomo.org/