تغییر مقیاس ویژگی
| یادگیری ماشین و دادهکاوی |
|---|
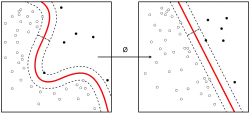 |
تغییر مقیاس ویژگی روشی است که برای نرمال کردن[الف] محدوده متغیرهای مستقل یا ویژگیهای دادهها استفاده میشود. در پردازش داده، به نرمالسازی داده نیز معروف است و عموماً در مرحله پیش پردازش دادهها انجام میشود.[۱]
انگیزه
از آنجایی که دامنه مقادیر دادههای خام پراکنده است، در برخی از الگوریتمهای یادگیری ماشین، مانند خوشهبندی، توابع هدف بدون نرمالسازی به درستی کار نمیکنند. به عنوان مثال، بسیاری از طبقهبندیکنندهها فاصله بین دو نقطه را با فاصله اقلیدسی محاسبه میکنند. اگر یکی از ویژگیها دارای طیف وسیعی از مقادیر باشد، فاصله توسط این ویژگی خاص کنترل میشود. بنابراین، محدوده همه ویژگیها باید به گونهای نرمال شود که هر ویژگی تقریباً سهم متناسبی در فاصله نهاییِ مورد استفاده در طبقهبندی داشته باشد.
دلیل دیگری که چرا تغییر مقیاس ویژگی اعمال میشود این است که گرادیان کاهشی با تغییر مقیاس ویژگی بسیار سریعتر از بدون آن همگرا میشود.[۲]
به ویژه اگر منظمسازی به عنوان بخشی از تابع ضرر به کار رود، استفاده از تغییر مقیاس ویژگی مهم است. (به طوری که ضرایب به طور مناسب تغییر کنند.)
روشها
تغییر مقیاس (نرمالسازی کمینه-بیشینه)
این تغییر مقیاس که در انگلیسی به آن min-max ساده ترین روش است و شامل تغییر مقیاس دامنه ویژگیها برای مقیاسبندی محدوده در [۰، ۱] یا [-۱، ۱] است. انتخاب محدوده هدف به ماهیت دادهها بستگی دارد. فرمول کلی برای تغییر مقیاس به [۰، ۱] به صورت زیر ارائه میشود:[۳]

که مقدار اصلی است، مقدار نرمال شده است. برای مثال، فرض کنید که دادههای وزن دانشآموزان را داریم که در محدوده [۸۰ کیلوگرم، ۱۲۰ کیلوگرم] قرار میگیرند. برای تغییر مقیاس این دادهها، ابتدا مقدار ۸۰ را از وزن هر دانشآموز کم کرده و نتیجه را بر ۴۰ (تفاوت بین حداکثر و حداقل وزن) تقسیم میکنم.


برای تغییر مقیاس یک محدوده بین یک مجموعه دلخواه از مقادیر [a, b]، فرمول به صورت زیر میشود:

که مقادیر کمینه و بیشینه هستند.

نرمالسازی میانگین

که یک مقدار اصلی است، مقدار نرمال شده است، میانگین آن بردار ویژگی است. شکل دیگری از نرمالسازی میانگین وجود دارد که بر انحراف معیار تقسیم میشود که به آن استانداردسازی نیز می گویند.

استانداردسازی (نرمالسازی Z-score)
در یادگیری ماشینی، ما میتوانیم انواع مختلفی از دادهها را مدیریت کنیم، بهعنوان مثال سیگنالهای صوتی و مقادیر پیکسل برای دادههای تصویر، و این دادهها میتواند شامل چند بعد باشد. استانداردسازی ویژگی باعث میشود که مقادیر هر ویژگی در دادهها دارای میانگین صفر[ب] (هنگام تفریق میانگین در عدد) و دارای واریانس واحد باشد. این روش به طور گسترده برای نرمالسازی در بسیاری از الگوریتمهای یادگیری ماشین (مانند ماشینهای بردار پشتیبان، رگرسیون لجستیک و شبکههای عصبی مصنوعی ) استفاده میشود.[۴] روش کلی محاسبه، تعیین میانگین توزیع و انحراف استاندارد برای هر ویژگی است. سپس میانگین را از هر ویژگی کم میکنم و مقادیر (میانگین قبلاً کم شده) هر ویژگی را بر انحراف معیار آن تقسیم میکنم.[۵]

که بردار ویژگی اصلی است، میانگین آن بردار ویژگی است و انحراف معیار آن است.

تغییر مقیاس به طول واحد
گزینه دیگری که به طور گسترده در یادگیری ماشینی استفاده میشود، تغییر مقیاس اجزای یک بردار ویژگی است به طوری که بردار دارای طول یک باشد. این معمولاً به معنای تقسیم هر جزء بر طول اقلیدسی بردار است:

در برخی کاربردها (مثلاً ویژگیهای هیستوگرام) استفاده از نرم L ۱ (یعنی هندسه تاکسی ) بردار ویژگی می تواند عملیتر باشد. این امر به ویژه در صورتی مهم است که در مراحل یادگیری زیر از متریک اسکالر به عنوان اندازهگیری فاصله استفاده شود. توجه داشته باشید که این فقط برای صدق میکند.

کاربرد
در گرادیان کاهشی تصادفی[پ]، مقیاسبندی ویژگی گاهی اوقات می تواند سرعت همگرایی الگوریتم را بهبود بخشد.[۶] در ماشینهای بردار پشتیبان (کوتهنوشت: SVM)، [۷] میتواند زمان یافتن بردارهای پشتیبان را کاهش دهد. توجه داشته باشید که تغییر مقیاس ویژگی، نتیجه SVM را تغییر می دهد.[۸]
جستارهای وابسته
منابع
- ↑ Ioffe, Sergey; Christian Szegedy (2015). "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift". arXiv:1502.03167 [cs.LG].
- ↑ Ioffe. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift". arXiv:1502.03167.
- ↑ "Min Max normalization". ml-concepts.com. Archived from the original on 5 April 2023. Retrieved 4 February 2023.
- ↑ "Min Max normalization". ml-concepts.com. Archived from the original on 2023-04-05. Retrieved 2022-12-14.
- ↑ Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome H. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction (به انگلیسی). Springer. ISBN 978-0-387-84884-6.
- ↑ "Gradient Descent, the Learning Rate, and the importance of Feature Scaling".
- ↑ Juszczak, P.; D. M. J. Tax; R. P. W. Dui (2002). "Feature scaling in support vector data descriptions". Proc. 8th Annu. Conf. Adv. School Comput. Imaging: 25–30. CiteSeerX 10.1.1.100.2524.
- ↑ Grus, Joel (2015). Data Science from Scratch. Sebastopol, CA: O'Reilly. pp. 99, 100. ISBN 978-1-491-90142-7.
- Ioffe, Sergey; Christian Szegedy (۲۰۱۵). "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift". arXiv:۱۵۰۲.۰۳۱۶۷ [cs.LG].
- "Min Max normalization". ml-concepts.com.
- Grus, Joel (۲۰۱۵). Data Science from Scratch. Sebastopol, CA: O'Reilly. pp. ۹۹, ۱۰۰. ISBN 978-1-491-90142-7.
- "Gradient Descent, the Learning Rate, and the importance of Feature Scaling".
- Juszczak, P.; D. M. J. Tax; R. P. W. Dui (۲۰۰۲). "Feature scaling in support vector data descriptions". Proc. ۸th Annu. Conf. Adv. School Comput. Imaging: ۲۵–۳۰. CiteSeerX ۱۰.۱.۱.۱۰۰.۲۵۲۴.
خواندن بیشتر
<ref> برای گروهی به نام «persian-alpha» وجود دارد، اما برچسب <references group="persian-alpha"/> متناظر پیدا نشد. ().