یادگیری تقویتی عمیق
یادگیری تقویت عمیق (RL عمیق) (به انگلیسی: Deep reinforcement learning) زیرمجموعه ای از یادگیری ماشین است که یادگیری تقویت (RL) و یادگیری عمیق را ترکیب میکند. RL مشکل یادگیری یک عامل محاسباتی را در نظر میگیرد تا با استفاده از آزمون و خطا تصمیم بگیرد. Deep RL یادگیری عمیق در راه حل را در بر میگیرد، به نمایندگان اجازه میدهد تا از دادههای ورودی بدون ساختار، بدون مهندسی دستی فضاهای حالت تصمیم بگیرند. الگوریتمهای Deep RL میتوانند ورودیهای بسیار بزرگی (مثلاً هر پیکسل ارائه شده روی صفحه در یک بازی ویدیویی) را بگیرند و تصمیم بگیرند که برای بهینهسازی یک هدف چه کارهایی انجام دهند (مثلاً به حداکثر رساندن امتیاز بازی). یادگیری تقویت عمیق برای مجموعه متنوعی از برنامهها از جمله رباتیک، بازیهای ویدیویی، پردازش زبان طبیعی، بینایی رایانه ای، آموزش، حمل و نقل، امور مالی و مراقبتهای بهداشتی مورد استفاده قرار گرفتهاست اما محدود به آنها نمیشود.[۱]
بررسی کلی
یادگیری عمیق
یادگیری عمیق نوعی یادگیری ماشینی است که با به کارگیری یک شبکه عصبی مجموعه ای از ورودیها را از طریق شبکه عصبی مصنوعی به مجموعه ای از خروجیها تبدیل می کند. نشان داده شدهاست که روشهای یادگیری عمیق، اغلب با استفاده از یادگیری نظارت شده با مجموعه دادههای برچسب دار، وظایفی را حل میکنند که شامل پردازش دادههای ورودی خام پیچیده و با ابعاد بالا مانند تصاویر، با مهندسی ویژگی دستی کمتر نسبت به روشهای قبلی است، و توانایی پیشرفت قابل توجهی در چندین زمینه از جمله کامپیوتر بینایی و پردازش زبان طبیعی دارد.
یادگیری تقویت
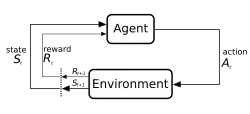
یادگیری تقویت فرآیندی است که در آن یک عامل یادمیگیرد که از طریق آزمون و خطا تصمیمگیری کند. این مشکل اغلب از نظر ریاضی به عنوان یک فرایند تصمیمگیری مارکوف (MDP) مدلسازی میشود، جایی که یک عامل در هر مرحله در یک حالت است ، اقدام میکند ، پاداش عددی دریافت میکند و به حالت بعدی منتقل میشود با توجه به پویایی محیط . عامل سعی میکند یک خط مشی را بیاموزد برای به حداکثر رساندن بازده آن (جمع پاداش مورد انتظار). در یادگیری تقویت (در مقابل کنترل بهینه) الگوریتم فقط به پویایی دسترسی دارد از طریق نمونهگیری





یادگیری تقویت عمیق
در بسیاری از مشکلات تصمیمگیری عملی، حالتهای از MDP دارای ابعاد بالا (به عنوان مثال تصاویر از یک دوربین یا جریان حسگر خام از یک ربات) است و با الگوریتمهای RL سنتی قابل حل نیست. الگوریتمهای یادگیری تقویت عمیق شامل یادگیری عمیق برای حل چنین MDPها هستند که اغلب نشان دهنده این خط مشی است یا سایر توابع آموخته شده به عنوان یک شبکه عصبی، و در حال توسعه الگوریتمهای تخصصیست که عملکرد خوبی در این تنظیمات دارند.
تاریخچه
همزمان با افزایش علاقه به شبکههای عصبی از اواسط دهه ۱۹۸۰، علاقه به یادگیری تقویت عمیق که در آن از یک شبکه عصبی برای نشان دادن سیاستها یا توابع ارزشی استفاده میشود، افزایش یافت. همانطور که در چنین سیستمی، کل فرایند تصمیمگیری از سنسورها تا موتورهای موجود در یک ربات یا عامل شامل یک شبکه عصبی تک لایه است، گاهی اوقات یادگیری تقویت انتها به انتها نامیده میشود. یکی از اولین برنامههای موفقیتآمیز یادگیری تقویت با شبکههای عصبی، TD-Gammon بود، یک برنامه کامپیوتری که در سال ۱۹۹۲ برای بازی تخته نرد تهیه شد.[۲] از چهار ورودی برای تعداد قطعات یک رنگ داده شده در یک مکان مشخص روی صفحه استفاده شدهاست که مجموعاً ۱۹۸ سیگنال ورودی است. با داشتن دانش صفر، این شبکه یادگرفت که بازی را در سطح متوسط با بازی خود و TD انجام دهد ()

کتابهای اصلی ساتن و بارتو در مورد یادگیری تقویت، برترسکاس و تسیتکلیس در مورد برنامهنویسی عصبی، و دانش و علاقه پیشرفته دیگران در این زمینه. گروه Katsunari Shibata نشان داد که توابع مختلفی در این چارچوب پدیدار میشوند،[۳] از جمله تشخیص تصویر، ثابت بودن رنگ، حرکت سنسور (تشخیص فعال)، هماهنگی چشم و حرکت دست، توضیح فعالیتهای مغز، دانش انتقال، حافظه، توجه انتخابی، پیشبینی و اکتشاف.
از حدود سال ۲۰۱۳، DeepMind نتایج یادگیری چشمگیری را با استفاده از RL عمیق برای انجام بازیهای ویدیویی Atari نشان داد.[۴] بازیکن کامپیوتر که یک شبکه عصبی با استفاده از یک الگوریتم RL عمیق آموزش دیدهاست، یک نسخه عمیق یادگیری Q که آنها را شبکههای Q عمیق (DQN) مینامند، با امتیاز بازی که به عنوان پاداش است. آنها از یک شبکه عصبی کانولوشن عمیق برای پردازش ۴ فریم پیکسل RGB (84x84) به عنوان ورودی استفاده کردند. تمام ۴۹ بازی با استفاده از همان معماری شبکه و با حداقل دانش قبلی، بهتر از روشهای رقابتی تقریباً در همه بازیها و عملکرد در سطحی قابل مقایسه یا برتر از یک تستر حرفه ای بازی انسانی، آموخته شدند.
هنگامی که AlphaGo ,[۵] یک برنامه رایانه ای آموزش دیده با RL عمیق برای بازی Go، اولین برنامه کامپیوتری Go شد که توانست یک بازیکن حرفه ای Go انسان را بدون نقص در یک صفحه کامل ۱۹ × ۱۹ شکست دهد، یادگیری تقویت عمیق به یک نقطه عطف رسید. در پروژه بعدی در سال ۲۰۱۷، AlphaZero عملکرد Go را بهبود بخشید و در عین حال نشان داد که میتوانند از همان الگوریتم برای یادگیری بازی شطرنج و شوگی در سطح رقابتی یا برتر از برنامههای رایانه ای موجود برای آن بازیها استفاده کنند. بهطور جداگانه، یک نقطه عطف دیگر توسط محققان دانشگاه کارنگی ملون در سال ۲۰۱۹ با توسعه دادن Pluribus به دست آمد که Pluribus، یک برنامه رایانه ای برای بازی پوکر که اولین کسی بود که در بازیهای چند نفره بدون محدودیت تگزاس موفق به شکست افراد حرفه ای شد. OpenAI Five، برنامه ای برای بازی پنج به پنج Dota 2 قهرمانان قبلی جهان را در یک مسابقه نمایشی در سال ۲۰۱۹ شکست داد.
همچنین یادگیری تقویت عمیق در بسیاری از حوزههای فراتر از بازیها اعمال شدهاست. در رباتیک از این رده استفاده شدهاست تا رباتها بتوانند کارهای ساده خانگی را انجام دهند[۶] و مکعب روبیک را با دست ربات حل کنند.[۷] Deep RL همچنین برنامههای پایداری را پیدا کردهاست که برای کاهش مصرف انرژی در مراکز داده استفاده میشود.[۸] Deep RL برای رانندگی خودمختار یک زمینه فعال تحقیقاتی در دانشگاه و صنعت است.
الگوریتمها
تکنیکهای مختلفی جهت آموزش سیاستها برای حل وظایف با الگوریتمهای یادگیری تقویت عمیق وجود دارد که هرکدام مزایای خاص خود را دارند. در بالاترین سطح، تمایزی بین یادگیری تقویتی مبتنی بر مدل و بدون مدل وجود دارد که به این موضوع اشاره دارد که آیا الگوریتم سعی در یادگیری یک مدل پیش رو از پویایی محیط دارد.
در الگوریتمهای یادگیری تقویت عمیق مبتنی بر مدل، یک مدل پیش رو از پویایی محیط، معمولاً با یادگیری نظارت شده با استفاده از یک شبکه عصبی تخمین زده میشود. سپس، اقدامات با استفاده از کنترل پیشبینی مدل با استفاده از مدل آموخته شده بدست میآیند. از آنجا که پویایی واقعی محیط معمولاً از پویایی آموخته شده جدا میشود، نماینده هنگام انجام اقدامات در محیط، غالباً دوباره برنامهریزی میکند. اقدامات انتخاب شده ممکن است با استفاده از روشهای مونت کارلو مانند روش آنتروپی متقابل یا ترکیبی از یادگیری مدل با روشهای بدون مدل بهینه شود.
در الگوریتمهای یادگیری تقویت عمیق بدون مدل، خط مشی بدون مدلسازی صریح پویایی رو به جلو یادگرفته میشود. یک خط مشی را میتوان برای به حداکثر رساندن بازده با برآورد مستقیم شیب خط مشی بهینهسازی کرد[۹] اما از واریانس بالایی رنج میبرد، و استفاده از آن را با تقریب عملکرد در RL عمیق غیر عملی میکند. الگوریتمهای بعدی برای یادگیری با ثبات تر ساخته شدهاند و بهطور گسترده استفاده میشوند. کلاس دیگری از الگوریتمهای یادگیری تقویت عمیق بدون مدل، متکی به برنامهنویسی پویا، الهام گرفته از یادگیری تفاوت زمانی و یادگیری Q است. در فضاهای عمل گسسته، این الگوریتمها معمولاً یک تابع Q شبکه عصبی را میآموزند که اقداماتی را برای بازدهی آینده تخمین میزند از دولت . در فضاهای مداوم، این الگوریتمها اغلب هم تخمین ارزش و هم خط مشی را یادمیگیرند.

پژوهش
یادگیری تقویت عمیق یک زمینه فعال تحقیقاتی است. در زیر برخی از خطوط اصلی تحقیق آمدهاست.
اکتشاف
یک عامل RL باید معامله اکتشاف / بهرهبرداری را متعادل کند: مسئله تصمیمگیری در مورد پیگیری اعمالی که قبلاً به آنها نشان داده میشود دارای پاداش بالایی هستند یا اقدامات دیگر را کشف میکنند تا پاداشهای بالاتری را کشف کند. عوامل RL معمولاً دادهها را با نوعی خط مشی اتفا مانند توزیع بولتزمن در فضاهای عمل گسسته یا توزیع گاوسی در فضاهای کنش مداوم جمعآوری میکنند که باعث ایجاد رفتار اکتشافی اساسی میشود. ایده کاوش مبتنی بر تازگی، یا کنجکاوی محور، انگیزه ای را برای نماینده فراهم میکند تا نتایج ناشناخته را کشف کند تا بهترین راه حلها را پیدا کند. این کار با «اصلاح [تابع از دست دادن (یا حتی ساختار شبکه) با افزودن اصطلاحات برای ایجاد انگیزه در اکتشاف» انجام میشود. همچنین ممکن است با استفاده از نمایش کارآزماییهای موفق یا شکلدادن پاداش ، به یک نماینده در کشف کمک شود ، و به یک نماینده پاداشهای میانه ای اختصاص دهید که متناسب با وظیفه ای که سعی در انجام آن دارد ، تنظیم شدهاست.
یادگیری تقویت خارج از سیاست
یک تمایز مهم در RL تفاوت بین الگوریتمهای on-policy است که نیاز به ارزیابی یا بهبود خط مشی جمعآوری دادهها دارد و الگوریتمهای خارج از سیاست که میتوانند خط مشی را از دادههای تولید شده توسط یک سیاست دلخواه یاد بگیرند. بهطور کلی ، روشهای مبتنی بر عملکرد بهتر برای یادگیری خارج از سیاست مناسب هستند و از کارایی نمونه بهتری برخوردار هستند - مقدار دادههای مورد نیاز برای یادگیری یک کار کاهش مییابد زیرا دادهها برای یادگیری دوباره استفاده میشوند. در نهایت ، RL آفلاین (یا "دسته ای") یادگیری خط مشی از یک مجموعه داده ثابت بدون تعامل اضافی با محیط را در نظر میگیرد.
یادگیری تقویت معکوس
RL معکوس به استنباط عملکرد پاداش یک عامل با توجه به رفتار عامل اشاره دارد. از یادگیری تقویت معکوس میتوان برای یادگیری از تظاهرات (یا یادگیری کارآموزی ) با استنباط پاداش تظاهرات کننده و سپس بهینهسازی سیاست برای به حداکثر رساندن بازده با RL استفاده کرد. رویکردهای یادگیری عمیق برای اشکال مختلف یادگیری تقلیدی و RL معکوس استفاده شدهاست.
یادگیری تقویت مشروط به هدف
یکی دیگر از حوزههای فعال تحقیقاتی ، یادگیری سیاستهای مبتنی بر هدف است که به آن سیاستهای متنی یا جهانی نیز گفته میشود که یک هدف اضافی را به عنوان ورودی برای برقراری یک هدف دلخواه به عامل در بر میگیرد . پخش مجدد تجربه عقاید روشی برای RL مشروط به هدف است که شامل ذخیرهسازی و یادگیری از تلاشهای ناموفق قبلی برای انجام یک کار است. اگرچه یک تلاش ناموفق ممکن است به هدف مورد نظر نرسیده باشد، اما میتواند درسی باشد برای چگونگی دستیابی به نتیجه ناخواسته از طریق برچسب گذاری مجدد عقب باشد.


یادگیری تقویت چند عاملی
بسیاری از کاربردهای یادگیری تقویت فقط شامل یک عامل تنها نیستند، بلکه شامل مجموعه ای از عوامل هستند که با هم یادمیگیرند و با یکدیگر سازگار میشوند. این عوامل ممکن است مانند بسیاری از بازیها، یا مانند بسیاری از سیستمهای چند عامل در دنیای واقعی، قابل رقابت باشند.
تعمیم
نوید استفاده از ابزارهای یادگیری عمیق در یادگیری تقویت، تعمیم است: توانایی عملکرد صحیح روی ورودیهایی که قبلاً دیده نشدهاست. به عنوان مثال، شبکههای عصبی آموزش دیده برای تشخیص تصویر میتوانند تشخیص دهند که یک عکس حاوی یک پرنده است حتی هرگز آن تصویر خاص یا حتی آن پرنده خاص را ندیدهاست. از آنجا که RL عمیق دادههای خام (به عنوان مثال پیکسلها) را به عنوان ورودی اجازه میدهد، نیاز به پیش تعریف محیط کاهش مییابد و این امکان وجود دارد که مدل به چندین برنامه تعمیم یابد. با استفاده از این لایه انتزاع، الگوریتمهای یادگیری تقویت عمیق میتوانند به گونه ای طراحی شوند که به آنها امکان عمومی بودن را بدهد و برای کارهای مختلف از یک مدل یکسان استفاده شود.[۱۰] یک روش افزایش توانایی سیاستهای آموزش دیده با سیاستهای RL عمیق برای تعمیم، تلفیق یادگیری نمایندگی است.
منابع
- ↑ Francois-Lavet, Vincent; Henderson, Peter; Islam, Riashat; Bellemare, Marc G.; Pineau, Joelle (2018). "An Introduction to Deep Reinforcement Learning". Foundations and Trends in Machine Learning. 11 (3–4): 219–354. arXiv:1811.12560. Bibcode:2018arXiv181112560F. doi:10.1561/2200000071. ISSN 1935-8237. S2CID 54434537.
- ↑ Tesauro, Gerald (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM. 38 (3): 58–68. doi:10.1145/203330.203343. S2CID 8763243. Archived from the original on 2010-02-09. Retrieved 2017-03-10.
- ↑ Shibata, Katsunari (March 7, 2017). "Functions that Emerge through End-to-End Reinforcement Learning". arXiv:1703.02239 [cs.AI].
- ↑ Mnih, Volodymyr; et al. (2015). "Human-level control through deep reinforcement learning". Nature. 518 (7540): 529–533. Bibcode:2015Natur.518..529M. doi:10.1038/nature14236. PMID 25719670. S2CID 205242740.
- ↑ Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; Driessche, George van den; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda; Lanctot, Marc; Dieleman, Sander; Grewe, Dominik; Nham, John; Kalchbrenner, Nal; Sutskever, Ilya; Lillicrap, Timothy; Leach, Madeleine; Kavukcuoglu, Koray; Graepel, Thore; Hassabis, Demis (28 January 2016). "Mastering the game of Go with deep neural networks and tree search". Nature. 529 (7587): 484–489. Bibcode:2016Natur.529..484S. doi:10.1038/nature16961. ISSN 0028-0836. PMID 26819042. S2CID 515925.

- ↑ Levine, Sergey; Finn, Chelsea; Darrell, Trevor; Abbeel, Pieter (January 2016). "End-to-end training of deep visuomotor policies" (PDF). JMLR. 17. arXiv:1504.00702.
- ↑ "OpenAI - Solving Rubik's Cube With A Robot Hand". OpenAI.
- ↑ "DeepMind AI Reduces Google Data Centre Cooling Bill by 40%". DeepMind.
- ↑ Williams, Ronald J (1992). "Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning". Machine Learning. 8 (3–4): 229–256. doi:10.1007/BF00992696. S2CID 2332513.
- ↑ Packer, Charles; Gao, Katelyn; Kos, Jernej; Krähenbühl, Philipp; Koltun, Vladlen; Song, Dawn (2019-03-15). "Assessing Generalization in Deep Reinforcement Learning". arXiv:1810.12282 [cs.LG].
- Demis, Hassabis (March 11, 2016). Artificial Intelligence and the Future (Speech).
- Sutton, Richard; Barto, Andrew (September 1996). Reinforcement Learning: An Introduction. Athena Scientific.
- Bertsekas, John; Tsitsiklis, Dimitri (September 1996). Neuro-Dynamic Programming. Athena Scientific. ISBN 1-886529-10-8.
- Miller, W. Thomas; Werbos, Paul; Sutton, Richard (1990). Neural Networks for Control.
- Shibata, Katsunari; Okabe, Yoichi (1997). Reinforcement Learning When Visual Sensory Signals are Directly Given as Inputs (PDF). International Conference on Neural Networks (ICNN) 1997. Archived from the original (PDF) on 2020-12-09. Retrieved 2020-12-01.
- Shibata, Katsunari; Iida, Masaru (2003). Acquisition of Box Pushing by Direct-Vision-Based Reinforcement Learning (PDF). SICE Annual Conference 2003. Archived from the original (PDF) on 2020-12-09. Retrieved 2020-12-01.
- Utsunomiya, Hiroki; Shibata, Katsunari (2008). Contextual Behavior and Internal Representations Acquired by Reinforcement Learning with a Recurrent Neural Network in a Continuous State and Action Space Task (PDF). International Conference on Neural Information Processing (ICONIP) '08. Archived from the original (PDF) on 2017-08-10. Retrieved 2020-12-14.
- Shibata, Katsunari; Kawano, Tomohiko (2008). Learning of Action Generation from Raw Camera Images in a Real-World-like Environment by Simple Coupling of Reinforcement Learning and a Neural Network (PDF). International Conference on Neural Information Processing (ICONIP) '08. Archived from the original (PDF) on 2020-12-11. Retrieved 2020-12-01.
- Mnih, Volodymyr; et al. (December 2013). Playing Atari with Deep Reinforcement Learning (PDF). NIPS Deep Learning Workshop 2013.
- OpenAI; et al. (2019). Solving Rubik's Cube with a Robot Hand. arXiv:1910.07113.
- "Machine Learning for Autonomous Driving Workshop @ NeurIPS 2021". NeurIPS 2021. December 2021.
- Schulman, John; Wolski, Filip; Dhariwal, Prafulla; Radford, Alec; Klimov, Oleg (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Schulman, John; Levine, Sergey; Moritz, Philipp; Jordan, Michael; Abbeel, Pieter (2015). Trust Region Policy Optimization. International Conference on Machine Learning (ICML). arXiv:1502.05477.
- Lillicrap, Timothy; Hunt, Jonathan; Pritzel, Alexander; Heess, Nicolas; Erez, Tom; Tassa, Yuval; Silver, David; Wierstra, Daan (2016). Continuous control with deep reinforcement learning. International Conference on Learning Representations (ICLR). arXiv:1509.02971.
- Mnih, Volodymyr; Puigdomenech Badia, Adria; Mirzi, Mehdi; Graves, Alex; Harley, Tim; Lillicrap, Timothy; Silver, David; Kavukcuoglu, Koray (2016). Asynchronous Methods for Deep Reinforcement Learning. International Conference on Machine Learning (ICML). arXiv:1602.01783.
- Haarnoja, Tuomas; Zhou, Aurick; Levine, Sergey; Abbeel, Pieter (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. International Conference on Machine Learning (ICML). arXiv:1801.01290.
- Andrychowicz, Marcin; Wolski, Filip; Ray, Alex; Schneider, Jonas; Fong, Rachel; Welinder, Peter; McGrew, Bob; Tobin, Josh; Abbeel, Pieter; Zaremba, Wojciech (2018). Hindsight Experience Replay. Advances in Neural Information Processing Systems (NeurIPS). arXiv:1707.01495.
- Schaul, Tom; Horgan, Daniel; Gregor, Karol; Silver, David (2015). Universal Value Function Approximators. International Conference on Machine Learning (ICML).
- Schrittwieser, Julian; Antonoglou, Ioannis; Hubert, Thomas; Simonyan, Karen; Sifre, Laurent; Schmitt, Simon; Guez, Arthur; Lockhart, Edward; Hassabis, Demis; Graepel, Thore; Lillicrap, Timothy; Silver, David (23 December 2020). "Mastering Atari, Go, chess and shogi by planning with a learned model". Nature. 588 (7839): 604–609. arXiv:1911.08265. Bibcode:2020Natur.588..604S. doi:10.1038/s41586-020-03051-4. PMID 33361790. S2CID 208158225.
- Bellemare, Marc; Candido, Salvatore; Castro, Pablo; Gong, Jun; Machado, Marlos; Moitra, Subhodeep; Ponda, Sameera; Wang, Ziyu (2 December 2020). "Autonomous navigation of stratospheric balloons using reinforcement learning". Nature. 588 (7836): 77–82. Bibcode:2020Natur.588...77B. doi:10.1038/s41586-020-2939-8. PMID 33268863. S2CID 227260253.
- Wulfmeier, Markus; Ondruska, Peter; Posner, Ingmar (2015). "Maximum Entropy Deep Inverse Reinforcement Learning". arXiv:1507.04888 [cs.LG].